
6 Led
2014
6 Led
'14
11:24
Hi Everyone,
I hope you had a terrific Christmas. Now, I know it's all work, but
after some time spent in the release candidate, CZ.NIC Labs are proud
to release Knot DNS 1.4.0 final version.
There have been a several bugfixes, odds and ends since the last
release candidate.
Namely NSEC3/transfer related bugs and case sensitivity of QNAME,
there's a link for an exhaustive list of changes below. But allow me
to reiterate what's new since the 1.3 version. Shall we?
Since the first beta, we have brought a new major feature on the
table. A technology preview of an automatic DNSSEC signing. Now, since
it's not a final product, there are still a few shortcomings; mainly
key management and auxiliary tools missing. However, that shouldn't
stop you from giving it a try! We've written a short "how to" on our
wiki page here:
https://gitlab.labs.nic.cz/labs/knot/wikis/dnssec-quickstart
But it's really as simple and creating signing keys and setting
"dnssec-enable on;"
There are few more enhancements like IDN in the utilities, zone serial policies
and fancier zone file printout. Plus a lot of changes under the bonnet. Say
for example the memory consumption, which is significantly lower (~35%
for our large zones). We've also doubled our (continuous) efforts in
producing both
unit and operational test cases, not to mention Knot DNS being kindly
accepted in the Coverity Scan program for open source software.
We've also spent some time on other related projects. Say the
comparison of the authoritative name servers, that you can find here:
https://www.knot-dns.cz/pages/benchmark.html
The whole effort is open source, you can try it yourself or even
create new test cases, any feedback is welcome.
https://gitlab.labs.nic.cz/labs/dns-benchmarking
With all that, the work is far from finished. We're going to further
polish the Knot DNS 1.4 features and prepare a new version at the same
time. By the way, we have a few surprises for you in that department
as well. Last but not least, we and the whole CZ.NIC Labs would like
to thank you, our users and supporters, who poured a lot of time into
helping us shape the Knot DNS the way it is. It's truly appreciated.
Here's a full change log:
https://gitlab.labs.nic.cz/labs/knot/blob/v1.4.0/NEWS
Sources:
https://secure.nic.cz/files/knot-dns/knot-1.4.0.tar.bz2
https://secure.nic.cz/files/knot-dns/knot-1.4.0.tar.gz
https://secure.nic.cz/files/knot-dns/knot-1.4.0.tar.xz
GPG signatures:
https://secure.nic.cz/files/knot-dns/knot-1.4.0.tar.bz2.asc
https://secure.nic.cz/files/knot-dns/knot-1.4.0.tar.gz.asc
https://secure.nic.cz/files/knot-dns/knot-1.4.0.tar.xz.asc
Kind Regards,
Marek, CZ.NIC Labs
--
Marek Vavruša Knot DNS
CZ.NIC Labs http://www.knot-dns.cz
-------------------------------------------
Americká 23, 120 00 Praha 2, Czech Republic
WWW: http://labs.nic.cz http://www.nic.cz

6 Led
6 Led
19:08
New subject: benchmarking (was: Re: Knot DNS 1.4.0 released!)
Marek Vavruša wrote:
We've also spent some time on other related
projects. Say the
comparison of the authoritative name servers, that you can find here:
https://www.knot-dns.cz/pages/benchmark.html
The whole effort is open source, you can try it yourself or even
create new test cases, any feedback is welcome.
https://gitlab.labs.nic.cz/labs/dns-benchmarking
Hi,
I wonder if you could publish more technical details about your
benchmark setup, especially the hardware CPU/NIC models, etc.? I see
you've tested "Intel 10 GbE" and "Intel 1GbE" network adapters,
but
these are large families of different hardware models. Apologies if I
overlooked these details somewhere.
I've recently been testing different models of Intel 1GbE adapters and
I've found a large variation in the maximum response rate that the same
DNS server can deliver depending on the network adapter -- for instance,
to take an extreme example, I was able to get over 100% more performance
from the latest Intel I350 "server" card against a very ancient Intel
82572EI "desktop" card, in an otherwise identical system. That is an
extreme example, but I still found large differences between the Intel
I210 and I217 adapters, which can be found together on a lot of current
generation single socket Xeon motherboards from Supermicro. And these
are all considered "Intel 1GbE" network adapters.
I would also be interested to know about the distribution of IP
addresses and port numbers in your benchmark DNS query traffic. If I
understand things correctly, Intel 1GbE (and probably 10GbE) adapters
that support multiple RX queues and "Receive Side Scaling" are usually
configured to select from the available RX queues based on a hash of
only the IP source and destination addresses, e.g.:
# ethtool -n <INTERFACE> rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
That may result in a single RX queue processing the incoming DNS queries
in a benchmark if the queries are all sourced from a single IP address,
which may be detrimental. It may be advantageous to configure the
network adapter to also hash over the source and destination ports, if
supported, e.g.:
# ethtool -N <INTERFACE> rx-flow-hash udp4 sdfn
# ethtool -n <INTERFACE> rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
L4 bytes 0 & 1 [TCP/UDP src port]
L4 bytes 2 & 3 [TCP/UDP dst port]
There are statistical counters available with the "ethtool -S" command
to verify if packets are being evenly balanced among the RX queues on a
network adapter with multiple RX queues.
It may also be advantageous to configure "Transmit Packet Steering" [0].
If I understand things correctly, network adapters with multiple TX
queues will only utilize a single TX queue until XPS is configured.
[0] http://www.mjmwired.net/kernel/Documentation/networking/scaling.txt#364
--
Robert Edmonds
edmonds(a)debian.org
21:20
New subject: benchmarking (was: Re: Knot DNS 1.4.0 released!)
Hi Robert,
I agree, I'm going to add the detailed machine configuration later (see below).
For the time being, here's what's most important.
Intel(R) Xeon(R) CPU X3430 @ 2.40GHz
Intel Corporation 82598EB 10-Gigabit
Intel Corporation 82571EB Gigabit
Broadcom Corporation NetXtreme BCM5723 Gigabit
I use RSS/RPS, and it works quite well, especially with IRQ affinity
distributed evenly across cores via the set_irq_affinity.sh [1] script
that they supply with the drivers. I don't use hashing over source
port though, and the reason is - the CPU is too slow to take any
benefit from it.
However, I've got one more modern server at the disposal, but it isn't
connected to the network yet, so I'll try it again later (memory is
also a bottleneck for more zones with hosting case, but that's another
business). Still, it seems to do it's job and I get both IRQ/CPUs and
TX/RX rings busy evenly (at least ifpps & ethtool -S tells me so). I
can't seem to get much tuning out of the Broadcom driver, but I didn't
try hard to be honest. I'm not sure now whether I tweaked the XPS or
not, but quick check tells me each CPU uses its own TX queue, so I
either did or Linux did some magic for me.
Now, I don't have a 10Gig switch here so I used to bridge two
interfaces together and do a separate player and receiver. As it turns
out, the packet pushing through the bridge skewed the results. So I
now have 1..N (2 at the moment) boxes that replay traffic each with
it's real address and catch the replies with iptables filter. It works
quite well with IRQs distribute, plus it a) scales b) brings variation
of source address.
You might also ask why do I use interrupt coalescing, the reason is
CPU again. I'd like it to process queries not just process interrupts.
All in all, I'm quite eager to do more tests when the new machine is
ready because there are perhaps a zillion of different things that
affect the results and I'm very curious to know. I thought this kind
of stuff is quite boring for people, so I tried to make it as brief as
possible (and it's still work in progress, I should update the website
really). And now it seems I let my mouth running too long, apologies.
Though if you happen to have any interesting results to share, I'm all
ears. I'd like to make this benchmark not just a "guys testing their
own stuff", but "yes, this is a correct way that gives me meaningful
results for my use case" thing. I hope it happens, the more people the
merrier.
[1] https://www.kernel.org/doc/Documentation/networking/ixgbe.txt
Best,
Marek
On 6 January 2014 19:08, Robert Edmonds <edmonds(a)debian.org> wrote:
Marek Vavruša wrote:
We've also spent some time on other related
projects. Say the
comparison of the authoritative name servers, that you can find here:
https://www.knot-dns.cz/pages/benchmark.html
The whole effort is open source, you can try it yourself or even
create new test cases, any feedback is welcome.
https://gitlab.labs.nic.cz/labs/dns-benchmarking
Hi,
I wonder if you could publish more technical details about your
benchmark setup, especially the hardware CPU/NIC models, etc.? I see
you've tested "Intel 10 GbE" and "Intel 1GbE" network adapters,
but
these are large families of different hardware models. Apologies if I
overlooked these details somewhere.
I've recently been testing different models of Intel 1GbE adapters and
I've found a large variation in the maximum response rate that the same
DNS server can deliver depending on the network adapter -- for instance,
to take an extreme example, I was able to get over 100% more performance
from the latest Intel I350 "server" card against a very ancient Intel
82572EI "desktop" card, in an otherwise identical system. That is an
extreme example, but I still found large differences between the Intel
I210 and I217 adapters, which can be found together on a lot of current
generation single socket Xeon motherboards from Supermicro. And these
are all considered "Intel 1GbE" network adapters.
I would also be interested to know about the distribution of IP
addresses and port numbers in your benchmark DNS query traffic. If I
understand things correctly, Intel 1GbE (and probably 10GbE) adapters
that support multiple RX queues and "Receive Side Scaling" are usually
configured to select from the available RX queues based on a hash of
only the IP source and destination addresses, e.g.:
# ethtool -n <INTERFACE> rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
That may result in a single RX queue processing the incoming DNS queries
in a benchmark if the queries are all sourced from a single IP address,
which may be detrimental. It may be advantageous to configure the
network adapter to also hash over the source and destination ports, if
supported, e.g.:
# ethtool -N <INTERFACE> rx-flow-hash udp4 sdfn
# ethtool -n <INTERFACE> rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
L4 bytes 0 & 1 [TCP/UDP src port]
L4 bytes 2 & 3 [TCP/UDP dst port]
There are statistical counters available with the "ethtool -S" command
to verify if packets are being evenly balanced among the RX queues on a
network adapter with multiple RX queues.
It may also be advantageous to configure "Transmit Packet Steering" [0].
If I understand things correctly, network adapters with multiple TX
queues will only utilize a single TX queue until XPS is configured.
[0] http://www.mjmwired.net/kernel/Documentation/networking/scaling.txt#364
--
Robert Edmonds
edmonds(a)debian.org
_______________________________________________
knot-dns-users mailing list
knot-dns-users(a)lists.nic.cz
https://lists.nic.cz/cgi-bin/mailman/listinfo/knot-dns-users
22:09
New subject: benchmarking (was: Re: Knot DNS 1.4.0 released!)
Marek Vavruša wrote:
Hi Robert,
I agree, I'm going to add the detailed machine configuration later (see below).
For the time being, here's what's most important.
Intel(R) Xeon(R) CPU X3430 @ 2.40GHz
Intel Corporation 82598EB 10-Gigabit
Intel Corporation 82571EB Gigabit
Broadcom Corporation NetXtreme BCM5723 Gigabit
Very interesting -- I believe the 82571EB is the dual port "server"
version of the single port "desktop" 82572EI controller that I tested.
This is a very old chipset (launched in 2005) and may be causing a
bottleneck in your tests:
http://ark.intel.com/products/20720/Intel-82571EB-Gigabit-Ethernet-Controll…
I tested an "Intel(R) Xeon(R) CPU E3-1245 v3 @ 3.40GHz" with the 82572EI
chipset and I was not able to get more than about 375K responses/second.
I think if you graph *responses* per second rather than queries per
second you might find something very interesting in your data. I took a
few of your data points for Knot DNS 1.4-dev (Root server, Intel 1 GbE)
and multiplied queries/second by response rate (which ought to give
responses/second):
>> 396500 * .907
359625.5
>> 484100 * .775
375177.5
>> 523700 * .737
385966.89999999997
>> 602100 * .646
388956.60000000003
>> 654400 * .595
389368.0
>> 847500 * .458
388155.0
>>
That's almost identical to the results/behavior I got, but I'm doing a
much different benchmark -- recursive DNS cache with repetitive queries
(so, 100% cache hit rate). And the CPU I'm testing is quite a bit
faster (quad core 2.4 GHz vs quad core 3.2 GHz + faster memory +
microarchitectural improvements). But both configurations (root server
vs 100% cache hit recursive server) ought to be able to illuminate
bottlenecks that are caused by the platform/hardware. So it is quite
suspicious that we both run into response rate bottlenecks that are
nearly identical numerically.
The interesting thing is that when my setup ran into this response rate
bottleneck, CPU usage kept going up as the query load increased, but the
response rate stayed the same. So I suspect the bottleneck is not
occurring on the input path, but rather on the output path. I started
looking into this with the dropwatch utility:
https://fedorahosted.org/dropwatch/
And that appeared to confirm my suspicion. It might be interesting to
compare the TX packet count as measured by the NIC (ifpps/ethtool)
versus the response message count as measured by the DNS server.
When I replaced the 82572EI controller with an Intel I350-T2:
http://ark.intel.com/products/59062/intel-ethernet-server-adapter-i350-t2
The exact same benchmark run jumped from ~375K responses/second to ~900K
responses/second. Everything else was identical except the network
card.
Of course, it is a very good result to find out that your DNS server is
too fast for your hardware :-)
--
Robert Edmonds
edmonds(a)debian.org
7 Led
7 Led
10:39
New subject: benchmarking (was: Re: Knot DNS 1.4.0 released!)
On 6 January 2014 22:09, Robert Edmonds <edmonds(a)debian.org> wrote:
This dropwatch seems interesting, I didn't know about it before!
But you're right about the difference in TX packet count versus the
number of packet that actually arrive,
I noticed the difference was immense with the bridged NICs (tcpreplay
told me roughly 1.1Mpps, but actually only 600k pps worth of traffic
arrived). Fishy. Without the bridge, around 900k pps arrived, but it's
still a difference, so the problem lies both in the input and the
output path. Big question is, how to reliably measure queries that
REALLY arrive without affecting the server performance? At the moment,
I chose to measure both transmitted queries and received answers at
the requestor box,
so the losses in networking are counted in.
Marek Vavruša wrote:
Hi Robert,
that is what I've thought so. Incidentally, I have the I350 in the new
server, so I'm eager to try it out.
Back then, we've bought the 10Gig cards hoping for significantly
better results - they are, but not at the level
I expected. I wonder if it's the age of the card or the CPU just can't
keep up, I admit I don't follow the latest NIC fashion.
Hi Robert,
I agree, I'm going to add the detailed machine configuration later (see below).
For the time being, here's what's most important.
Intel(R) Xeon(R) CPU X3430 @ 2.40GHz
Intel Corporation 82598EB 10-Gigabit
Intel Corporation 82571EB Gigabit
Broadcom Corporation NetXtreme BCM5723 Gigabit
Very interesting -- I believe the 82571EB is the dual port "server"
version of the single port "desktop" 82572EI controller that I tested.
This is a very old chipset (launched in 2005) and may be causing a
bottleneck in your tests:
http://ark.intel.com/products/20720/Intel-82571EB-Gigabit-Ethernet-Controll… I tested an "Intel(R) Xeon(R) CPU E3-1245 v3 @
3.40GHz" with the 82572EI
chipset and I was not able to get more than about 375K responses/second.
I think if you graph *responses* per second rather than queries per
second you might find something very interesting in your data. I took a
few of your data points for Knot DNS 1.4-dev (Root server, Intel 1 GbE)
and multiplied queries/second by response rate (which ought to give
responses/second):
Well, we do graph responses answered, so if you do the math as below,
it's all there.
The reason why I let the benchmark replay at higher rates than it is
possible to handle is,
that I wan't to see if there are any dips or weird behavior when I tip
it over the edge.
Perhaps I could plot the maximum sustained response rate as well somewhere?
>> 396500 * .907
359625.5
>> 484100 * .775
375177.5
>> 523700 * .737
385966.89999999997
>> 602100 * .646
388956.60000000003
>> 654400 * .595
389368.0
>> 847500 * .458
388155.0
>>
That's almost identical to the results/behavior I got, but I'm doing a
much different benchmark -- recursive DNS cache with repetitive queries
(so, 100% cache hit rate). And the CPU I'm testing is quite a bit
faster (quad core 2.4 GHz vs quad core 3.2 GHz + faster memory +
microarchitectural improvements). But both configurations (root server
vs 100% cache hit recursive server) ought to be able to illuminate
bottlenecks that are caused by the platform/hardware. So it is quite
suspicious that we both run into response rate bottlenecks that are
nearly identical numerically.
The interesting thing is that when my setup ran into this response rate
bottleneck, CPU usage kept going up as the query load increased, but the
response rate stayed the same. So I suspect the bottleneck is not
occurring on the input path, but rather on the output path. I started
looking into this with the dropwatch utility:
https://fedorahosted.org/dropwatch/
And that appeared to confirm my suspicion. It might be interesting to
compare the TX packet count as measured by the NIC (ifpps/ethtool)
versus the response message count as measured by the DNS server.
When I replaced the 82572EI controller with an Intel I350-T2:
http://ark.intel.com/products/59062/intel-ethernet-server-adapter-i350-t2
The exact same benchmark run jumped from ~375K responses/second to ~900K
responses/second. Everything else was identical except the network
card.
Of course, it is a very good result to find out that your DNS server is
too fast for your hardware :-)
--
Robert Edmonds
edmonds(a)debian.org
Now you made me even more eager to try out the I350 if it is as good
as it seems :)
Ultimately, I'd like more people to join in with the benchmarking
because we can't afford to buy every piece of NIC out there,
so crowdsourcing this seems like the best solution. In the end, with
enough data, people would have a quite accurate idea about the
performance on their machine or what kind of NIC should they buy, not
just a pretty graph.
Best,
Marek
_______________________________________________
knot-dns-users mailing list
knot-dns-users(a)lists.nic.cz
https://lists.nic.cz/cgi-bin/mailman/listinfo/knot-dns-users
8 Led
8 Led
4:32
New subject: benchmarking (was: Re: Knot DNS 1.4.0 released!)
Marek Vavruša wrote:
My benchmark setup uses a sender and receiver directly connected with a
crossover cable (no switch), and RX/TX flow control disabled, so the
statistics counters built into the NICs ought to correspond precisely
with one another: the TX count on one is the RX count on the other, and
vice versa. The TX/RX packet counters on the NICs ought to be very
accurate: they're measured by the hardware and should only be
incrementing if actual packets are occurring on the wire. If the
counters on the two machines don't correspond, then there's a problem in
the physical layer or the hardware or its driver.
If the DNS server counts the queries it receives and the responses it
sends on its server socket, it should be easy to compare those counters
against the NIC TX/RX packet counters. If they don't correspond, then
that can help pinpoint the problem. I think BIND and Unbound have those
kinds of query/response message counters, not sure about Knot. Message
counters ought to be very cheap if they're kept on a per-thread basis
(no cache line bouncing) and only aggregated periodically.
On 6 January 2014 22:09, Robert Edmonds
<edmonds(a)debian.org> wrote:
Actually, what you're graphing is the proportion of queries answered,
which is not the same as graphing the raw number of responses sent per
second. Sorry if I'm not being clear.
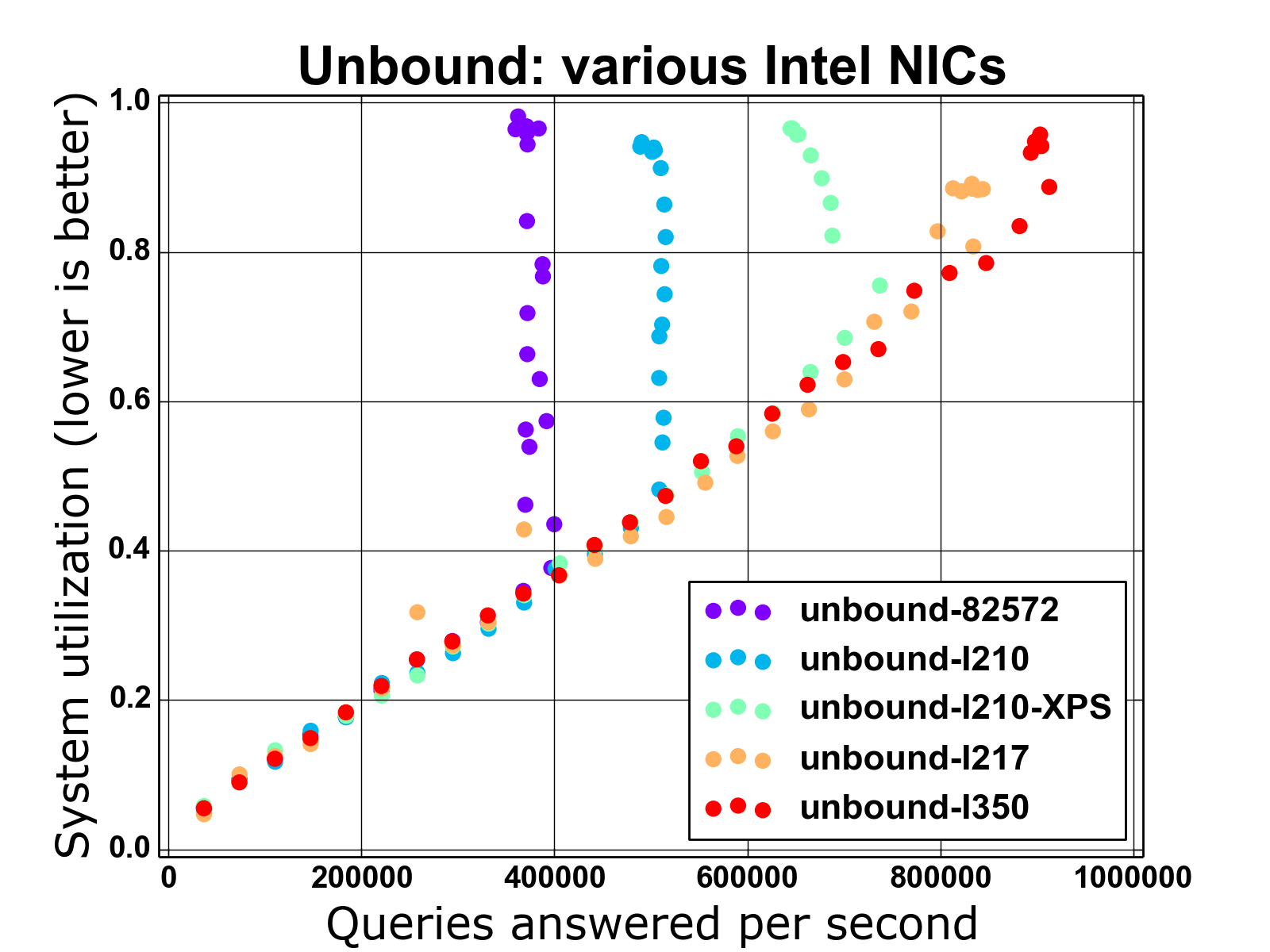
I've attached a graph showing the performance of another DNS server with
various NICs to illustrate what I mean. The axes are CPU utilization
(1.0 meaning all CPUs utilized) and responses/second. There is a third
variable, queries/second, which isn't shown -- you have to know that the
benchmark setup increases q/s at a constant rate, so the "ideal" plot
would show linear behavior with plot points evenly spaced horizontally.
I think this style of visualization more readily shows performance
barriers, which you can see as a sharp change to vertically stacked data
points in some of the plots. (You don't have to do any math to notice
the performance barrier.) The equivalent in a response rate proportion
plot shows a more gradual decline starting from 100%, which may be
deceptive. OTOH, graphing just the responses/sec doesn't do a good job
at showing when dropped queries occur. (You can sort of infer dropped
queries based on horizontal compression of the data points, though.)
I tested an "Intel(R) Xeon(R) CPU E3-1245 v3
@ 3.40GHz" with the 82572EI
chipset and I was not able to get more than about 375K responses/second.
I think if you graph *responses* per second rather than queries per
second you might find something very interesting in your data. I took a
few of your data points for Knot DNS 1.4-dev (Root server, Intel 1 GbE)
and multiplied queries/second by response rate (which ought to give
responses/second):
Well, we do graph responses answered, so if you do the math as below,
it's all there. The reason why I let the benchmark replay at higher
rates than it is
possible to handle is, that I wan't to see if there are any dips or
weird behavior when I tip it over the edge.
Yes, finding weird behavior is definitely one of my motivations for the
round of benchmarks that I'm currently working on. Graphing CPU usage
against responses/second can show other interesting behavior, like bad
scalability: ideally there should be a linear shape to the CPU plot
instead of a concave one. Concavity might indicate some kind of
contention is occurring. And, obviously you can directly compare two
different servers head-to-head to see which is using more CPU.
Perhaps I could plot the maximum sustained response
rate as well somewhere?
I'm not sure where it would go. Not a whole lot of room on a graph with
a half-dozen runs. Visualization is hard :-)
That's
almost identical to the results/behavior I got, but I'm doing a
much different benchmark -- recursive DNS cache with repetitive queries
(so, 100% cache hit rate). And the CPU I'm testing is quite a bit
faster (quad core 2.4 GHz vs quad core 3.2 GHz + faster memory +
microarchitectural improvements). But both configurations (root server
vs 100% cache hit recursive server) ought to be able to illuminate
bottlenecks that are caused by the platform/hardware. So it is quite
suspicious that we both run into response rate bottlenecks that are
nearly identical numerically.
The interesting thing is that when my setup ran into this response rate
bottleneck, CPU usage kept going up as the query load increased, but the
response rate stayed the same. So I suspect the bottleneck is not
occurring on the input path, but rather on the output path. I started
looking into this with the dropwatch utility:
https://fedorahosted.org/dropwatch/
And that appeared to confirm my suspicion. It might be interesting to
compare the TX packet count as measured by the NIC (ifpps/ethtool)
versus the response message count as measured by the DNS server.
This dropwatch seems interesting, I didn't know about it before!
But you're right about the difference in TX packet count versus the
number of packet that actually arrive,
I noticed the difference was immense with the bridged NICs (tcpreplay
told me roughly 1.1Mpps, but actually only 600k pps worth of traffic
arrived). Fishy. Without the bridge, around 900k pps arrived, but it's
still a difference, so the problem lies both in the input and the
output path. Big question is, how to reliably measure queries that
REALLY arrive without affecting the server performance? At the moment,
I chose to measure both transmitted queries and received answers at
the requestor box,
so the losses in networking are counted in. Ultimately, I'd like more people to join in with
the benchmarking
because we can't afford to buy every piece of NIC out there,
so crowdsourcing this seems like the best solution. In the end, with
enough data, people would have a quite accurate idea about the
performance on their machine or what kind of NIC should they buy, not
just a pretty graph.
Or even which DNS server they should use based on which one uses the
least CPU :-)
--
Robert Edmonds
edmonds(a)debian.org
{kind=link}
4459
days inactive
4461
days old
5 comments
2 participants
participants (2)
-
 Marek Vavruša
Marek Vavruša -
 Robert Edmonds
Robert Edmonds